
Vowels / உயிரெழுத்துக்கள்


Consonants / மெய்யெழுத்துக்கள்




Gateway to Ancient Literary Treasures from Grandha Scripts

Intention
A platform that can help to create a personal digital library of literature from ancient scripts.
Language in scope will be Grandha which will get translated to Tamil / English.

Solution Overview
Build personalized digital repository that helps to embrace traditions.
Unlock a wealth of knowledge and insights tailored to the personal interests and heritage.
Demonstrate technical capability on Computer Vision/ AI technology in a unique way.

Execution Methodology
A reading engine for scanning handwritten scripts, documents, and ancient architectural structures such as temple walls.
This will have capability that will seamlessly compile and present translated text in both Tamil and English.
Explore possibility of collaborating with “Veda Padasalas” to engage students in solution building.
This will provide an opportunity for them to learn and apply emerging technologies.

7th-century inscription in Grandha script at the Mandagapattu Hindu temple

Early 7th century Mandagapattu temple is dedicated to Brahma-Shiva-Vishnu, situated in the village of Mandagapattu in the Viluppuram district of Tamil Nadu, India. The temple is notable for the earliest known rock-cut Sanskrit inscription written in Grandha script. It is attributed to the Pallava king Mahendravarman.
Grandha Reader – Concept document
- The goal is to build a solution that can read text which are written Grandha language and translate into Tamil.
- Facilitate a way to create digital library platform from sacred literature is the purpose.
- Purpose is to embrace tradition and to gain knowledge from literature that are written in Grandha.
- This reader could also be in help to the students who are learning Grandha.
- This can also help in availability of the information to wider audience.
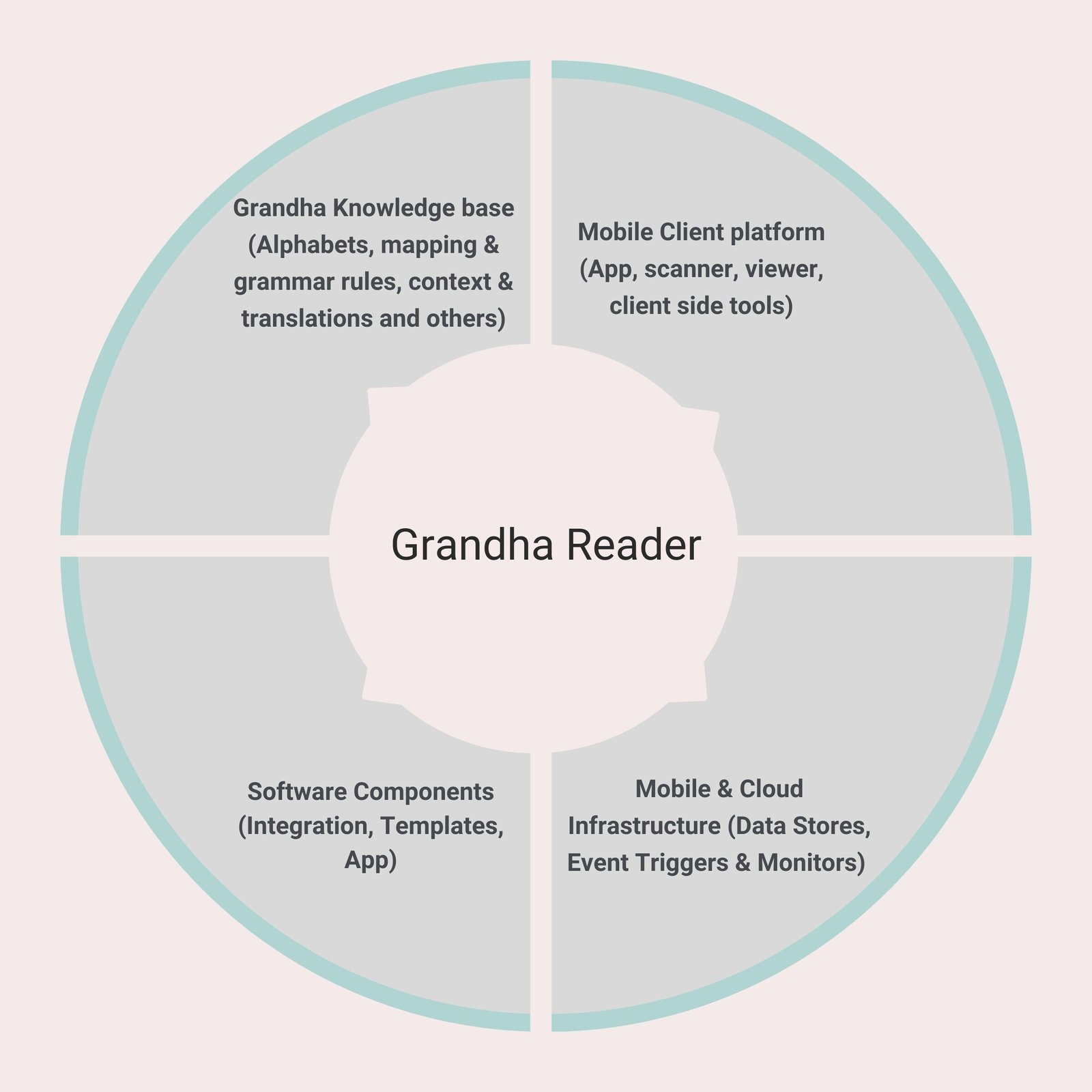
The approach is to build a set of components that can scan text and store it in a repository on the cloud. There will be a mapping engine that will create mapped text into Tamil. Based on context setting and translation rules, a reader software will present it in Tamil. This will have four major parts.
- Grandha knowlege base will be a collection of basic alphabets, mapping rules, grammar rules. Progressively contextual information will be built into the knowledge base. Based on this, an attempt will be made to translate and present them in Tamil. Future goal will be to apply AI principles that can work as a suggestion engine for missing words / alphabets while reading the text.
- Mobile platform will be used to scan text from various sources. The text could be available in books, handwritten scripts, temple walls, palm leaves and other places. A progressive attempt will be made to build scanning facility across the above data sources. The mobile platform will also be used to present the text in Tamil based on the information in the servers.
- Cloud infrastructure will be used for data stores and communication / API connectivity components and other web servers.
- Software components group consists of engine that gets input from client platforms and apply mapping / translation rules. These SDKs / libraries will have capability to convert grandha text into Tamil. Progressively multiple level of complexity handling intelligence will be added to the engine.